|
Not the four-dimensional cube sort of Tesseract, this is the
Optical Character Recognition (OCR) "Tesseract", software that
takes an image of some lettering and produces a plain text
file containing the text.
Or not. It's well-known that this is "Actually Quite Hard(tm)"
and Tesseract does a pretty good job "Out of the Box" with very
little messing about. But the other day I ran across something
that has me utterly baffled. Let me share my bebafflement with
you.

Original
|
Here's an image that I want to convert to plain text. To the
eye it's looks pretty straight-forward, and I have quite a few
examples that, to the eye, look almost identical, and which
tesseract handles without a problem.
This one, however, produces this result:
TUE 03/04/2018
BBC TWO
rFsE10
0h30m (DR)
|
OK, it's not so bad for three of the lines, but the third line?
Where does that come from? How does it get that?
(Hah! One commenter has said that on the third line if you
screw up your eyes and squint you might be able to see "rFsE10"
in the background, in the "black", not in the foreground. Maybe,
just maybe, that explains where "rFsE10" comes from.)
Well, I'm accustomed to this, and I played with the settings for
a bit, and I played with the image for a bit, but if the settings
were right for this image, they turned out to be wrong for another,
and I have a lot of these that I need to convert as a batch, so I
need settings that will work for them all.
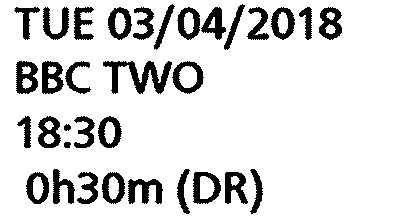
Processed
|
So I read the "man page" for tesseract, and discovered the
"get.images" option. This will dump to a file the image it ends
up using. So I did that, and I got the result you see here. It's
clean, it's binary, and it's clearly legible. So why is it getting
the answer so wrong?
Then I thought - "Aha! Let's feed that image into tesseract!"
And that's when I got my first surprise. Feeding this image, the
one tesseract created, back into tesseract, the answer was this:
TUE 03/04/2018
BBC TWO
18:30
Oh30m (DR)
|
How can that be different ?!?
The image is the one tesseract output, which we can only assume
is the one it's using for the character recognition, and yet it
gives a different (and beautifully correct!) answer!
I'm ... well ... stunned! And stumped. Why should this be so?
|
OK, a number of people have been in touch to say that
they don't follow my reasoning. My guess is that most people
won't care, so I'm reluctant to extend this page, but if you
are confused as to why I am so confused then please, please
let me know and I'll write up a more detailed description.
To me this just defies common sense, and to paraphrase Niels Bohr:
"If this behaviour of tesseract hasn't profoundly shocked you,
you haven't understand it yet." |
And in case you're wondering, if you repeat this process and feed
the processed image into tesseract and ask for a dump, you get
back exactly the same image. So that really is the one it's using
second time round, but even though it outputs it first time round,
it's not the one it's using.
Does that make sense to you?
It doesn't make sense to me.
Send us a comment ...
|  Suggest a change ( <--
What does this mean?) /
Send me email
Suggest a change ( <--
What does this mean?) /
Send me email Subscribe!
Subscribe!
